Productivity Assessment of Neural Code Completion (+ Copilot)
Key points from the summary:
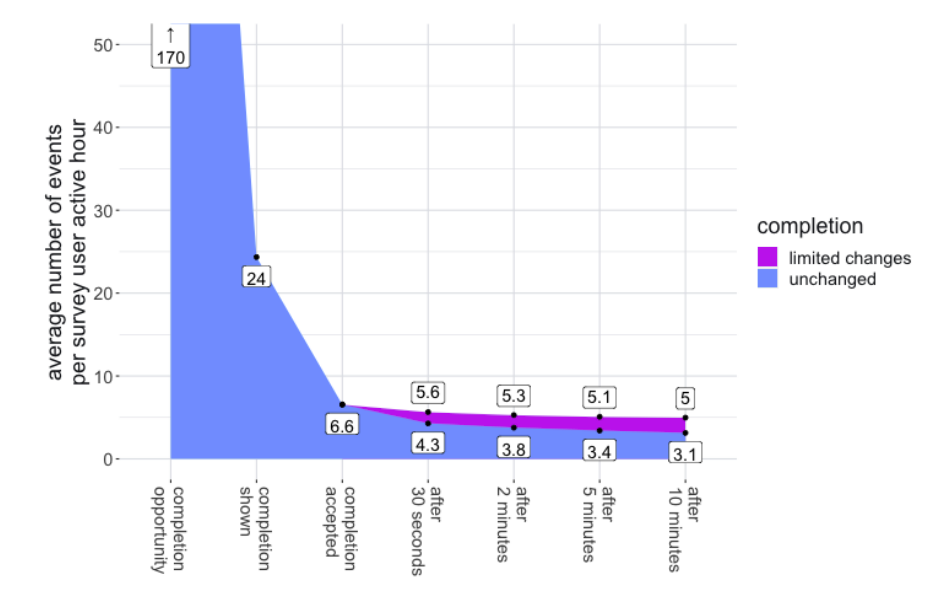
- Copilot looks for opportunities to do code completion. Often, these opportunities do not lead to completions being shown (e.g. because the user keeps on typing). See figure below.
- Acceptance rate is lower in standard working hours. There are some theories, but unconfirmed.
Key caveats of the paper:
- Correlation is not causation
- The amount of these trends that are explained is quite low
- Self-perceptions of productivity don’t necessarily reflect objective productivity
- Acceptance rate is not the only metric optimized for
How does Copilot decide the length of completion?
- There’s a tradeoff between single-line vs. multi-line completions, Copilot tries to hit the sweet spot
- They are doing experiments to find weaker points of Copilot (e.g. try/catch statements)
- They have not tested this on other tasks like writing docstrings
- Usually, they use the same stopping criteria as in GPT (like enforcing a max length, looking for double newlines), and then do post-hoc trimming off of the end
How did Copilot decide what size of model to use?
- Largely based on intuition a few years ago, though with new advances they might reevaluate
- Need to make sure latency is ~ 200 ms
- For models other than completion (test generation, documentation), larger models are used because these aren’t as time-sensitive
What about privacy and security concerns?
- One constraint is that Copilot can innovate based on their telemetry, but not on user code. In fact, they do not any of the user code while finetuning.
- In addition, there are security concerns from larger companies
Do they do retrieval?
- A first version that is currently used is to just check files that are open
- They do string similarity matching from chunks in other open files
- There is no neural encoder (unlike a lot of the latest work in retrieval)
Could we do some reprompting based on errors?
- This is hard because Copilot has to perform completions fast
- However, there is a lot of offline evaluation of this
- For example, they have done offline evaluation to try to get generated code to pass unit tests
- However, running arbitrary code in the wild is scary!
- There is also work based on guessing execution info without executing the code which they hope to incorporate
Will there be future features like editing, repair, etc?
- Yes! Check out Copilot labs and Code Brushes
Will Copilot be able to learn your personalized coding style?
- Code brushes supports a feature where you can define a custom code prompt that gets fed into the language model
- If you have a lot of typos in your code, it will likely come up with more typos (because of the nature of prompting)